中国のAIは米国に対して半年遅れとも言われているが、これは米国のAIを使って訓練をしているオリジナル性の無いもので、このデータはクラウドなどよって違法に手に入れたデータを使っている。米国がこれを止めると3~4年以上の遅れとなるという。この為に米国のサーバーの使用を阻止する法案が米国議会に提出されている。
このように米国と中国の間のAI開発を巡る攻防は、まさに今、法律の制定や技術的な制限を含めて非常に激しい局面を迎えている。
1.中国のAIは「半年遅れ」なのか?(米国のデータ流用問題)
元Googleのエリック・シュミット氏や、Google DeepMindのデミス・ハサビスCEO、さらには米国のシンクタンク(外交問題評議会など)の直近の分析でも、「中国のAIは米国に対して約3〜8ヶ月(およそ半年)の遅れで追従している」というのが共通認識になっている。中国のDeepSeek社が発表した最新モデル「DeepSeek V4」なども、この時間差の範囲内にあるとされている。
しかし、この「半年遅れ」を維持できている背景には、米国の最先端AIモデルのデータを流用している(技術用語で「蒸留:Distillation」や「モデル抽出」と呼ぶ)という事実がある。
• 手法の実態: 中国のAI開発者は、米国のOpenAI(ChatGPT)やAnthropic(Claude)などの高度な商用AIに膨大な質問を投げ、その「賢い回答データ」を丸ごと自国のAIの学習データとして利用している。
• 違法性と米政府の反発: 米国政府(ホワイトハウス科学技術政策局)や米大手AI各社は、これを「国家規模での組織的な蒸留攻撃であり、不当な知的財産の強奪(実質的な違法行為)」であると公式に非難している。米国の frontier モデル(最先端モデル)の開発には数千億円の投資と数万個の超高性能半導体が必要となるが、中国側はその「結果(回答データ)」だけを安価に吸い上げることで、莫大なコストと時間をショートカットしているのだった。
専門家の試算では、もしこの米国製AIからのデータ抽出(吸い上げ)を完全に遮断できれば、中国のAI開発は自力で基礎から研究し直さなければならなくなるため、遅れは「数ヶ月」から「3〜4年以上」に一気に拡大すると言われている。
2.「クラウドの抜け穴」と違法サーバー利用の阻止法案
米国は中国への最先端AI半導体(NVIDIA製の高級チップなど)の輸出を厳しく禁止しているが、中国企業にはこれまで大きな「抜け穴(ループホール)」があった。それがクラウド経由のリモート利用だ。
物理的にチップを中国に輸出しなくても、中国の会社が「東南アジアや中東、あるいは米国内にあるデータセンター」のクラウドサービスを契約し、ネット越しにNVIDIAの最新チップ(Blackwellなど)をレンタルしてAIの訓練を行っていたのだった。これは法律上「製品の輸出」に当たらなかったため、合法的なグレーゾーンとして利用されていた。
これらを阻止するために、米国議会で超党派で可決・進められているのが以下の重要な法案だ。
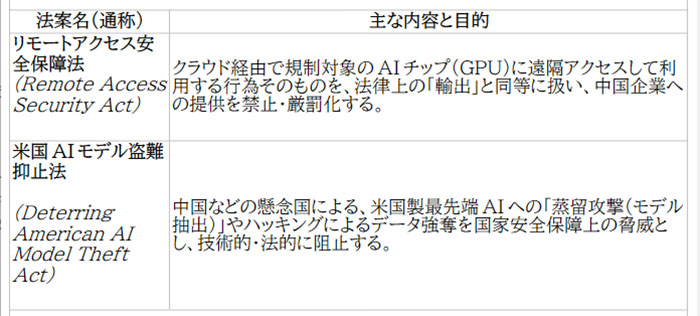
実際、米国下院ではこれらの法案が圧倒的な多数(369対22など)で可決されており、可決に伴って司法省(DOJ)も数千億円規模のAIサーバーを中国へ不正に迂回ルートで提供しようとした業者を摘発するなど、法執行の動きが本格化している。
3.今後の展開:本当に「3〜4年」引き離せるのか?
米国側が「データの吸い上げ(蒸留)」と「クラウド経由のチップ利用」の双方を完全に締め出そうとしている今、米中のAI格差が今後どうなるかについては、2つの見方がある。
• 米国主導のシナリオ(格差拡大): 米国の思惑通りにデータ抽出とクラウド利用が止まれば、中国は自国の限られた半導体とデータだけで開発せざるを得なくなる。米国では、最先端AIが「自ら次のAIを設計して進化を加速させるフェーズ」に入りつつあるため、中国を3〜4年以上引き離して独走できるという見立てだ。
• 中国の粘り(独自の効率化): 一方で、中国(DeepSeekなど)は限られた半導体や予算のなかで「信じられないほど効率的にAIを動かす独自のソフトウェア技術」を編み出すことに長けている。また、完全にデータを遮断することは技術的に難しく、完全に引き離すのは容易ではないという警戒感も米国側には根強く残っている。
まとめ
中国のAIは米国の高度なAIの回答データを大量に流用することで、開発期間を大幅にショートカットしてきた。米国議会はこれを「不当な技術の盗用」とみなし、クラウド経由でのサーバー利用やデータ抽出を直接禁止する強力な法案を次々と成立させている。この網の目が完全に機能すれば、中国の遅れが年単位に広がる可能性は十分にある。