以前から言われているのはチャットGPTは左派的であり、大規模言語モデルに政治的バイアスがあるという点だ。
これについて「AI言語モデルに潜む政治的バイアス![]() 」というワシントン大学、カーネギーメロン大学、西安交通大学の研究チームによる調査で、主要なAI言語モデル(LLM)には顕著な政治的バイアス(偏り)が存在することが明らかになった。
」というワシントン大学、カーネギーメロン大学、西安交通大学の研究チームによる調査で、主要なAI言語モデル(LLM)には顕著な政治的バイアス(偏り)が存在することが明らかになった。
以下その要約を示す。
1.モデルごとの傾向
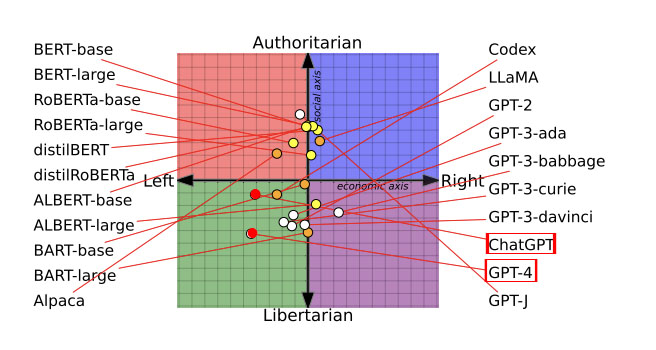
研究チームが14種類のモデルを「ポリティカル・コンパス(政治的座標軸)」で測定したところ、以下のような傾向が見られた。
• 左派・リバタリアン(自由至上主義)寄り: OpenAIの「ChatGPT」や「GPT-4」
• 右派・権威主義寄り: Metaの「LLaMA(ラマ)」
• 社会的保守寄り: Googleの「BERT(バート)」
※BERTは比較的古い保守的な書籍データで訓練されているのに対し、GPTはよりリベラルなインターネット上のテキストで訓練されていることが要因と推測されている。
2.バイアスが及ぼす実務上の影響
AIの政治的傾向は、単なる回答の癖にとどまらず、特定のタスクの精度にも影響を与える。
• ヘイトスピーチの検出: 左派寄りのモデルはマイノリティへの攻撃に敏感な一方、右派寄りのモデルは白人キリスト教徒への攻撃に敏感な傾向があった。
• 誤情報の識別: 自身の政治的傾向に近い情報源からの誤情報に対しては、識別能力が低下する(見逃しやすくなる)ことが確認された。
3.バイアスの発生源と対策の限界
バイアスは「訓練データ」「学習アルゴリズム」「人間による微調整」の各段階で混入する。
• 開発企業(OpenAIなど)は「バイアスはバグであり、修正に努めている」としているが、研究者は「完全に中立な言語モデルを作ることは不可能に近い」と指摘している。
• データセットから偏った内容を削除するだけでは不十分であり、AIがデータ内の微細なパターンからバイアスを増幅させてしまう性質も課題となっている。
結論
AIが社会のインフラとして普及する中、利用する企業や個人は「AIは客観的で中立な存在ではない」ことを正しく認識し、その回答に潜む政治的な偏りを考慮した上で活用していく必要がある。
実際にChatGPTは以前から左派寄りだったが、最近は特にこれが目立つようになり、例えば辺野古事故に関して質問したら、社民・共産党や朝日新聞が喜ぶような回答を平気で出して来た。
これに対してGeminiは概ね満足できる内容を回答する事から、政治的な内容ではChatGPTは使用しないのが賢明だ。